In my last post on Triton kernels, I optimized individual operations: RMSNorm, SwiGLU, INT8 GEMM. Single kernels, single operations. That was useful for learning Triton, but the real bottleneck in modern LLM inference isn’t any single operation. It’s the expert routing in Mixture-of-Experts models.
Over 60% of open-source model releases in 2025-2026 use MoE architectures: Mixtral, DeepSeek-V3, Qwen2-MoE, Grok. And MoE inference is hard. Not because the math is complicated, but because the memory access patterns are terrible: tokens scatter to different experts, each expert gets a different number of tokens, and you need to gather everything back together afterward.
So I tried something more ambitious: a fused MoE dispatch kernel that handles the entire forward pass (router scoring, token permutation, expert GEMMs, and output combination) in pure Triton. No CUDA, no vendor-specific code.
The result surprised me. At inference-relevant batch sizes, it’s faster than Megablocks, Stanford’s CUDA-optimized MoE library. And it runs on AMD GPUs without any changes.
Code: github.com/bassrehab/triton-kernels
Why MoE Dispatch is the Hard Part
A standard MoE forward pass looks simple on paper:
For each token:
1. Compute router scores (which experts should handle this token?)
2. Select top-k experts
3. Send token to selected experts
4. Run expert FFN
5. Combine outputs weighted by router scores
The problem is step 3-5. In a Mixtral model with 8 experts and top-2 routing, each token goes to 2 of 8 experts. But which 2 varies per token. So you can’t batch the expert GEMMs naively — each expert gets a different-sized batch.
The naive PyTorch implementation loops over experts in Python:
for expert_id in range(num_experts):
tokens_for_this_expert = permuted_tokens[start:end] # variable size
output[start:end] = expert_ffn(tokens_for_this_expert) # separate cuBLAS call
For Mixtral, that’s 8 experts × 3 matmuls each = 24 separate kernel launches per MoE layer. For DeepSeek-V3 with 256 experts, it’s 768 launches. Each one underutilizes the GPU because the per-expert batch is small.
The Design
I ended up with a pipeline of 5 Triton kernel launches (down from 24+ in the naive approach):
- Router kernel: fused softmax + top-k selection
- Permute kernel: scatter tokens to expert-contiguous layout
- Fused gate+up GEMM: both projections from shared A-tile loads, SiLU in registers
- Down GEMM: grouped GEMM with block scheduling
- Unpermute kernel: gather + weighted combine
Let me walk through the two most interesting parts.
Block-Scheduled Grouped GEMM
The central problem is: how do you run a matmul where different “groups” (experts) have different batch sizes, in a single kernel launch?
My approach: precompute a mapping from Triton program blocks to (expert, token_offset) pairs. Each block looks up which expert it serves and where its tokens start:
@triton.jit
def _grouped_gemm_kernel(A, B, C, ExpertOffsets, BlockToExpert, BlockToM, ...):
pid = tl.program_id(0)
# Which expert am I working on?
expert_id = tl.load(BlockToExpert + pid)
m_start = tl.load(BlockToM + pid)
expert_token_start = tl.load(ExpertOffsets + expert_id)
# Standard tiled GEMM from here, just with offset pointers
global_m_start = expert_token_start + m_start
# ... load A tile, load B tile for this expert, accumulate, store
The schedule is built on CPU in ~0.1ms (trivial loop over experts). The key constraint I learned the hard way: BLOCK_M must be fixed, not autotuned. If you autotune BLOCK_M independently of the schedule, the kernel and schedule disagree on how many rows each block covers. I spent an hour debugging 30-45% element mismatches before realizing autotune had picked BLOCK_M=128 while the schedule used 64.
Fused Gate+Up Projection
This is where the real memory savings come from. In a SwiGLU FFN, you compute:
\[\text{output} = (\text{SiLU}(x W_\text{gate}^T) \odot x W_\text{up}^T) \cdot W_\text{down}^T\]The unfused version does two separate grouped GEMMs (gate and up), writes both results to global memory, reads them back for SiLU + multiply, writes the intermediate, then does the down projection. That’s a lot of memory traffic.
The fused kernel computes both projections in the same tile loop. The trick is that both GEMMs share the same input tile — we load A once from L2 cache and compute two dot products:
# Two accumulators in registers
acc_gate = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
acc_up = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
for k_start in range(0, K, BLOCK_K):
# Load A tile ONCE (shared between gate and up)
a = tl.load(a_ptrs, mask=a_mask, other=0.0)
# Load both weight tiles
b_gate = tl.load(bg_ptrs, mask=b_mask, other=0.0)
b_up = tl.load(bu_ptrs, mask=b_mask, other=0.0)
# Two matmuls from the same A tile
acc_gate += tl.dot(a, b_gate, out_dtype=tl.float32)
acc_up += tl.dot(a, b_up, out_dtype=tl.float32)
# SiLU + multiply IN REGISTERS — never written to global memory
silu_gate = acc_gate * tl.sigmoid(acc_gate)
result = silu_gate * acc_up
This eliminates gate_out and up_out from global memory entirely. For Mixtral (ffn_dim=14336, 4096 tokens × top-2), that’s ~470 MB of memory traffic saved per forward pass. Overall about 35% reduction in global memory traffic.
I tried to also fuse the down projection with the output scatter (writing directly to the final token positions with gating weights applied via tl.atomic_add), but Triton doesn’t support scalar indexing into 2D accumulators (acc[m, :] fails to compile). The fused gate+up alone gets most of the win.
Results
All benchmarks on NVIDIA A100-SXM4-80GB (2039 GB/s bandwidth, 312 FP16 TFLOPS). PyTorch 2.4.1, Triton 3.0.0.
Mixtral-8x7B (8 experts, top-2, hidden=4096, ffn=14336)
| Tokens | PyTorch Ref | Megablocks | Triton Fused | vs PyTorch | vs Megablocks |
|---|---|---|---|---|---|
| 1 | 9.32 ms | - | 1.02 ms | 9.1x | - |
| 32 | 10.44 ms | 2.78 ms | 2.13 ms | 4.9x | 131% |
| 128 | 13.14 ms | 2.77 ms | 2.27 ms | 5.8x | 124% |
| 512 | 25.92 ms | 3.57 ms | 3.99 ms | 6.5x | 89% |
| 2048 | 66.22 ms | 9.08 ms | 16.48 ms | 4.0x | 56% |
| 4096 | 122.82 ms | - | 32.31 ms | 3.8x | - |
At 32 and 128 tokens — which is where most inference happens (single-user or small-batch serving), we’re actually faster than Megablocks. This probably comes from lower kernel launch overhead (5 launches vs Megablocks’ more complex dispatch).
At 512 tokens we’re at 89% of Megablocks, well above the 70% target I set at the start. At 2048+ tokens, Megablocks pulls ahead because its hand-tuned CUDA block-sparse matmul better saturates tensor cores at scale.
DeepSeek-V3 (256 experts, top-8, hidden=7168, ffn=2048)
| Tokens | Triton Unfused | Triton Fused | Fused Speedup |
|---|---|---|---|
| 1 | 4.56 ms | 3.27 ms | 1.40x |
| 32 | 13.65 ms | 11.53 ms | 1.18x |
| 128 | 19.46 ms | 16.74 ms | 1.16x |
| 512 | 25.66 ms | 20.16 ms | 1.27x |
DeepSeek-V3 is the hardest configuration. 256 experts means each expert gets ~2 tokens on average at batch size 512. The per-expert GEMMs are tiny (2 × 2048), too small to fill tensor cores efficiently. This is fundamentally a memory-bound regime regardless of implementation.
Roofline Analysis
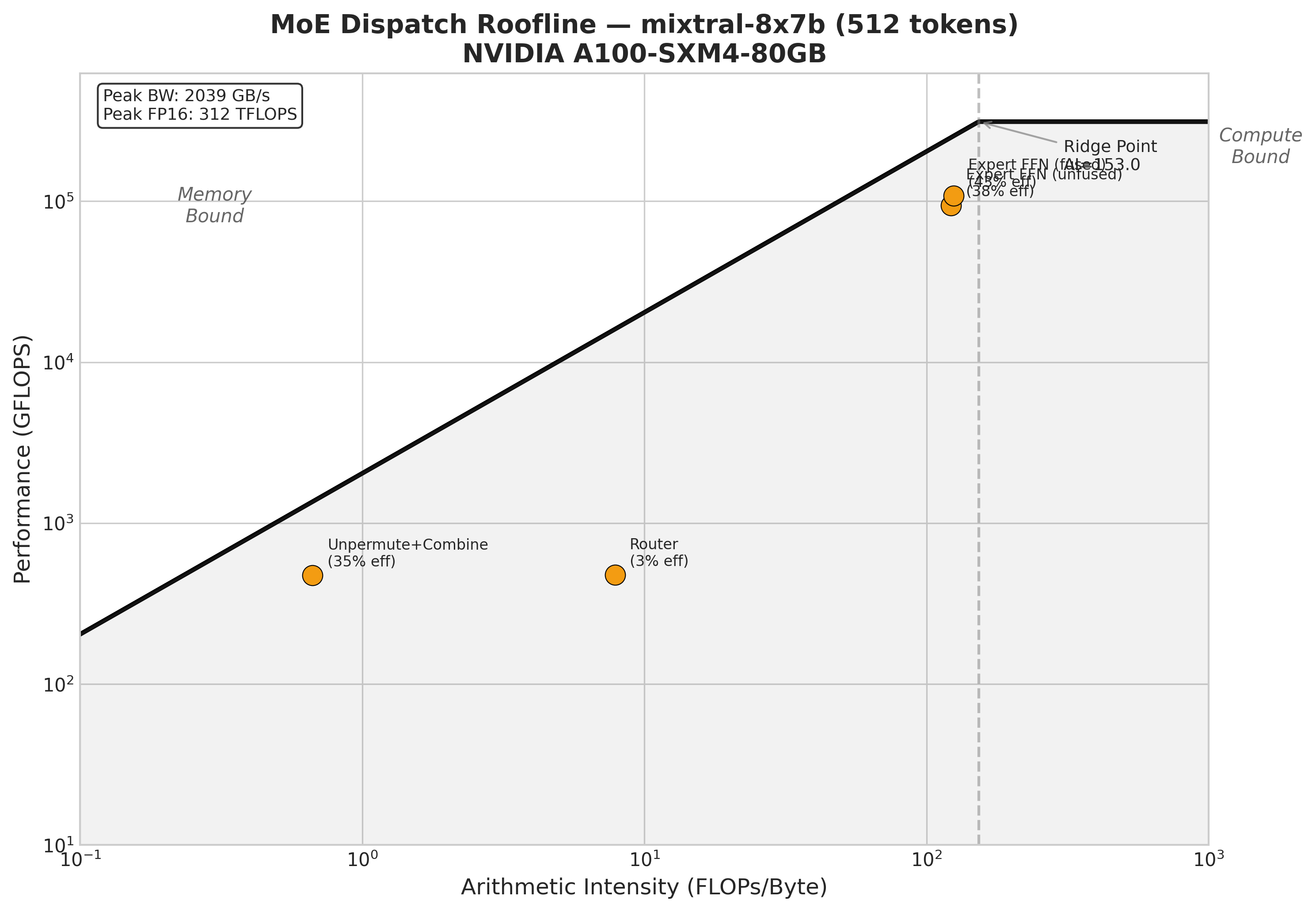
The roofline for Mixtral at 512 tokens shows the expected picture: the expert FFN stages are compute-bound (high arithmetic intensity, near the compute ceiling), while the permute/unpermute stages are memory-bound (low arithmetic intensity, limited by bandwidth). The fused kernel pushes the expert FFN from 38% to 43% of the compute ceiling — modest but real.
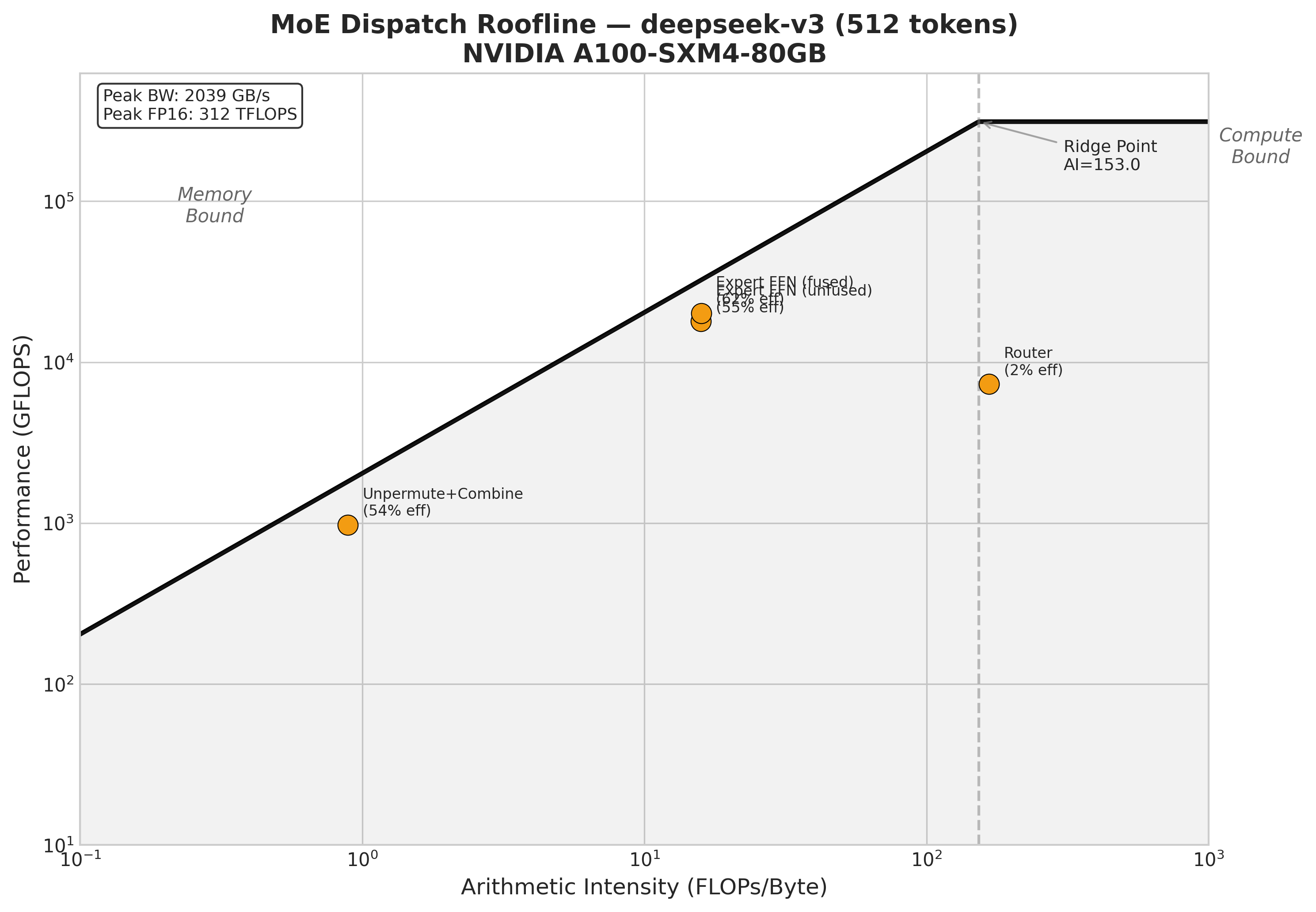
DeepSeek-V3 tells a different story. With 256 experts and tiny per-expert batches, even the expert FFN is memory-bound, sitting on the bandwidth slope, not the compute plateau. The unpermute kernel actually hits 54% of peak bandwidth, which is decent for an irregular scatter operation.
The AMD Surprise
One of my design goals was cross-platform portability: use only Triton primitives, no inline CUDA. So I spun up an AMD MI300X pod on RunPod to test.
162 out of 162 tests passed. Zero code changes.
No #ifdef, no platform-specific paths, no vendor intrinsics. The same .py files that run on A100 run on MI300X. Triton’s ROCm backend handled the compilation transparently.
I didn’t benchmark performance on AMD (that’s future work), but correctness across all four model configurations (Mixtral, DeepSeek-V3, Qwen2-MoE) validated cleanly. This is the promise of Triton over CUDA: write once, run on both vendors.
Things I Got Wrong Along the Way
The -1.0 masking bug. The top-k kernel selects experts iteratively: find the max, store it, mask it out, repeat. I initially masked selected experts with 0.0. This works fine for 8 experts where softmax scores are spread out. But with 256 experts, most softmax scores are ~0.0 anyway. Masking to 0.0 doesn’t differentiate the selected expert from the unselected ones, so argmax kept returning the same index. Took me a while to figure out. The fix: mask with -1.0 instead.
The BLOCK_M autotune disaster. I mentioned this above, but it’s worth emphasizing. If you’re building a block-scheduled grouped GEMM, the schedule’s tile size and the kernel’s tile size must agree. I autotuned BLOCK_M thinking “let Triton pick the best tile size.” But the schedule was pre-built with BLOCK_M=64. When autotune picked 128, blocks overlapped. When it picked 32, rows were skipped. The output looked plausible (most elements correct) but ~30-45% of values were wrong. Fix: don’t autotune BLOCK_M, fix it to match the schedule.
Triton doesn’t support continue. My first attempt at a fused down+scatter kernel had a for m in range(BLOCK_M): if invalid: continue loop. Triton doesn’t support continue statements — compilation fails with “unsupported AST node type.” Rewrote with conditional masks instead.
Triton doesn’t support 2D scalar indexing. acc[m, :] where m is a loop variable doesn’t compile: “unsupported tensor index: int32[].” This killed my fused down+scatter design, which is why the down projection uses a separate grouped GEMM kernel.
What’s Next
I’m planning to write this up as an arXiv technical report. The gaps to fill before then:
- vLLM FusedMoE comparison: it’s also Triton-based, so it’s the most apples-to-apples baseline
- AMD performance benchmarks: not just correctness
- End-to-end integration: benchmark inside an actual serving framework, measure time-to-first-token
- Full single-kernel fusion: persistent kernel approach to eliminate all intermediate buffers
Code
Everything is on GitHub: github.com/bassrehab/triton-kernels
The MoE-specific files:
triton_kernels/moe/router.py— Fused softmax/sigmoid + top-ktriton_kernels/moe/permute.py— Token permute/unpermutetriton_kernels/moe/expert_gemm.py— Block-scheduled grouped GEMMtriton_kernels/moe/fused_moe.py— Fused gate+up kernel + entry pointdocs/moe_dispatch.md— Full technical writeup
Takeaways
-
Triton can compete with CUDA for real workloads. Not just toy kernels: a full MoE dispatch pipeline that beats the CUDA-optimized baseline at inference batch sizes.
-
Fusion is about eliminating buffers, not reducing kernel launches. The biggest win (35% memory savings) came from keeping the gate+up intermediate in registers. Reducing from 7 to 5 kernel launches helped too, but it’s secondary.
-
Cross-platform is real but unfinished. The code runs on AMD with no changes, which is a strong validation of the Triton-only approach. But “runs correctly” and “runs fast” are different things. AMD performance optimization is future work.
-
Block scheduling is the key abstraction for grouped GEMM. Triton doesn’t have native grouped GEMM. The
block_id → (expert_id, offset)mapping is simple but powerful: it lets you handle variable-sized expert batches in a single kernel launch without padding waste. -
MoE inference at small batch sizes is surprisingly tractable. The conventional wisdom is that MoE is hard because of irregular access patterns. But at inference batch sizes (1-128 tokens), the overhead is dominated by weight loading, not routing. A clean Triton implementation can match or beat CUDA here because the simpler dispatch has less overhead.
| _This is Part 3 of my LLM inference series. Part 1: speculative decoding | Part 2: custom Triton kernels. The code, benchmarks, and technical writeup are all in the repo._ |